

Since my blog about Strava Fitness and Freshness has been very popular, I thought it would be interesting to demonstrate a simple model that can help you use these metrics to improve your cycling performance.
As a quick reminder, Strava’s Fitness measure is an exponentially weighted average of your daily Training Load, over the last six weeks or so. Assuming you are using a power meter, it is important to use a correctly calibrated estimate of your Functional Threshold Power (FTP) to obtain an accurate value for the Training Load of each ride. This ensures that a maximal-effort one hour ride gives a value of 100. The exponential weighting means that the benefit of a training ride decays over time, so a hard ride last week has less impact on today’s Fitness than a hard ride yesterday. In fact, if you do nothing, Fitness decays at a rate of about 2.5% per day.
Although Fitness is a time-weighted average, a simple rule of thumb is that your Fitness Score equates to your average daily Training Load over the last month or so. For example, a Fitness level of 50 is consistent with an average daily Training Load (including rest days) of 50. It may be easier to think of this in terms of a total Training Load of 350 per week, which might include a longer ride of 150, a medium ride of 100 and a couple of shorter rides with a Training Load of 50.
How to get fitter
The way to get fitter is to increase your Training Load. This can be achieved by riding at a higher intensity, increasing the duration of rides or including extra rides. But this needs to be done in a structured way in order be effective. Periodisation is an approach that has been tried and tested over the years. A four-week cycle would typically include three weekly blocks of higher training load, followed by an easier week of recovery. Strava’s Fitness score provides a measure of your progress.
Modelling Fitness and Fatigue
An exponentially weighted moving average is very easy to model, because it evolves like a Markov Process, having the following property, relating to yesterday’s value and today’s Training Load.
where
 is Fitness or Fatigue on day t and
is Fitness or Fatigue on day t and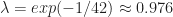 for Fitness or
for Fitness or  for Fatigue
for FatigueThis is why your Fitness falls by about 2.4% and your Fatigue eases by about 13.3% after a rest day. The formula makes it straightforward to predict the impact of a training plan stretching out into the future. It is also possible to determine what Training Load is required to achieve a target level of Fitness improvement of a specific time period.
Ramping up your Fitness
The change in Fitness over the next seven days is called a weekly “ramp”. Aiming for a weekly ramp of 5 would be very ambitious. It turns out that you would need to increase your daily Training Load by 33. That is a substantial extra Training Load of 231 over the next week, particularly because Training Load automatically takes account of a rider’s FTP.
Interestingly, this increase in Training Load is the same, regardless of your starting Fitness. However, stepping up an average Training Load from 30 to 63 per day would require a doubling of work done over the next week, whereas for someone starting at 60, moving up to 93 per day would require a 54% increase in effort for the week.
In both cases, a cyclist would typically require two additional hard training rides, resulting in an accumulation of fatigue, which is picked up by Strava’s Fatigue score. This is a much shorter term moving average of your recent Training Load, over the last week or so. If we assume that you start with a Fatigue score equal to your Fitness score, an increase of 33 in daily Training Load would cause your Fatigue to rise by 21 over the week. If you managed to sustain this over the week, your Form (Fitness minus Fatigue) would fall from zero to -16. Here’s a summary of all the numbers mentioned so far.

Whilst it might be possible to do this for a week, the regime would be very hard to sustain over a three-week block, particularly because you would be going into the second week with significant accumulated fatigue. Training sessions and race performance tend to be compromised when Form drops below -20. Furthermore, if you have increased your Fitness by 5 over a week, you will need to increase Training Load by another 231 for the following week to continue the same upward trajectory, then increase again for the third week. So we conclude that a weekly ramp of 5 is not sustainable over three weeks. Something of the order of 2 or 3 may be more reasonable.
A steady increase in Fitness
Consider a rider with a Fitness level of 30, who would have a weekly Training Load of around 210 (7 times 30). This might be five weekly commutes and a longer ride on the weekend. A periodised monthly plan could include a ramp of 2, steadily increasing Training Load for three weeks followed by a recovery week of -1, as follows.

This gives a net increase in Fitness of 5 over the month. Fatigue has also risen by 5, but since the rider is fitter, Form ends the month at zero, ready to start the next block of training.
To simplify the calculations, I assumed the same Training Load every day in each week. This is unrealistic in practice, because all athletes need a rest day and training needs to mix up the duration and intensity of individual rides. The fine tuning of weekly rides is a subject for another blog.
A tougher training block
A rider engaging in a higher level of training, with a Fitness score of 60, may be able to manage weekly ramps of 3, before the recovery week. The following Training Plan would raise Fitness to 67, with sufficient recovery to bring Form back to positive at the end of the month.

A general plan
The interesting thing about this analysis is that the outcomes of the plans are independent of a rider’s starting Fitness. This is a consequence of the Markov property. So if we describe the ambitious plan as [3,3,3,-2], a rider will see a Fitness improvement of 7, from whatever initial value prevailed: starting at 30, Fitness would go to 37, while the rider starting at 60 would rise to 67.
Similarly, if Form begins at zero, i.e. the starting values of Fitness and Fatigue are equal, then the [3,3,3,-2] plan will always result in a in a net change of 6 in Fatigue over the four weeks.
In the same way, (assuming initial Form of zero) the moderate plan of [2,2,2,-1] would give any rider a net increase of Fitness and Fatigue of 5.
Use this spreadsheet to experiment.











 and
and  determine the colour of the pixel at position (
determine the colour of the pixel at position (













 This is a common problem in signal processing, where the
This is a common problem in signal processing, where the 






 In the
In the 







