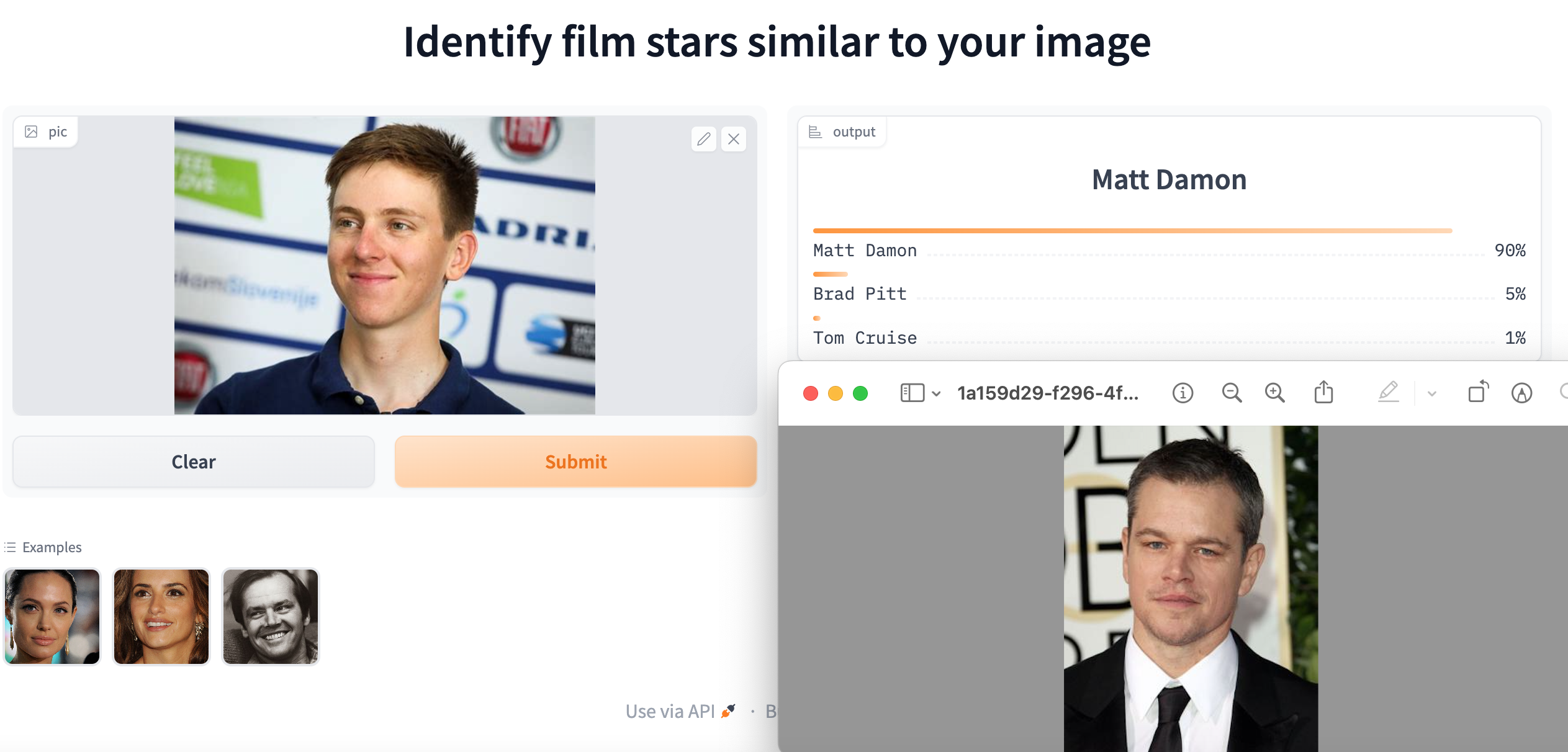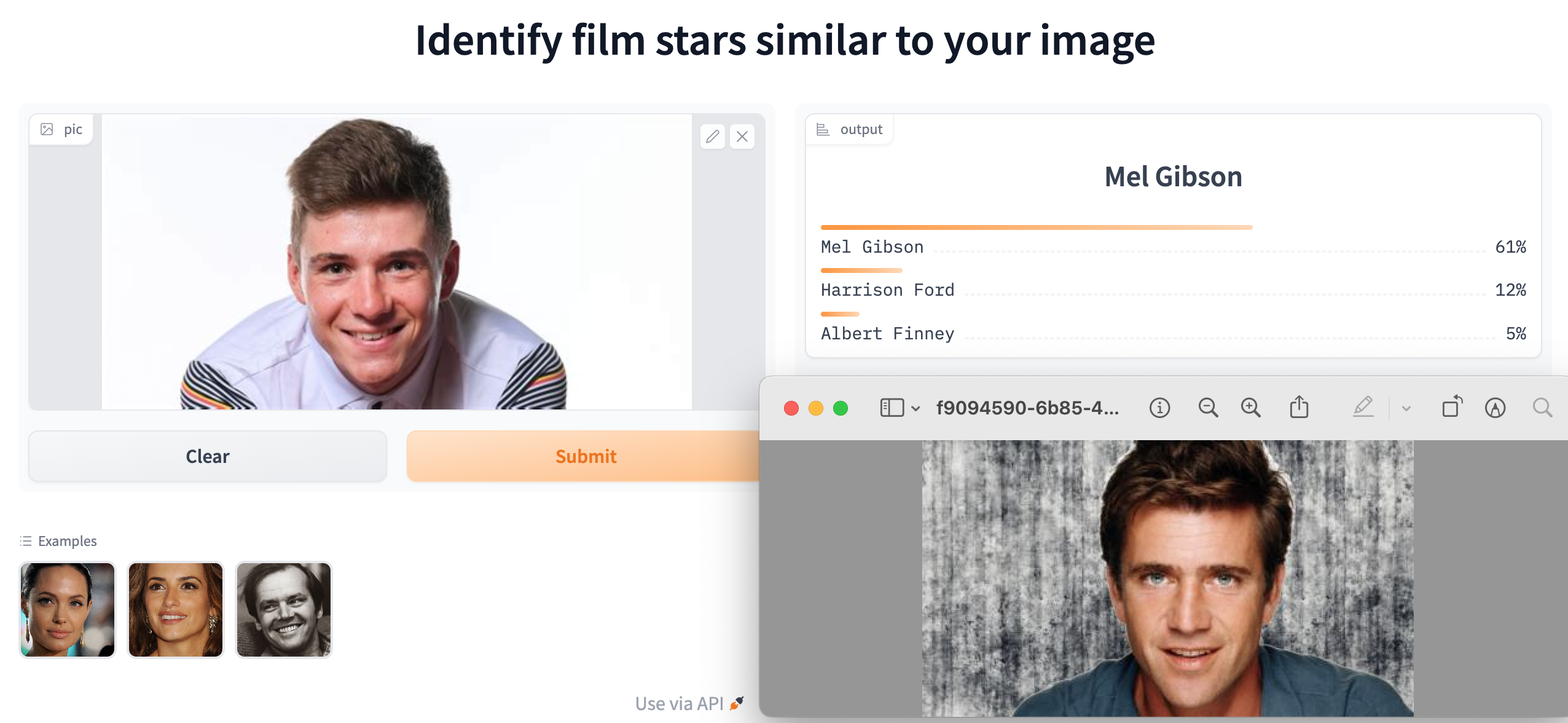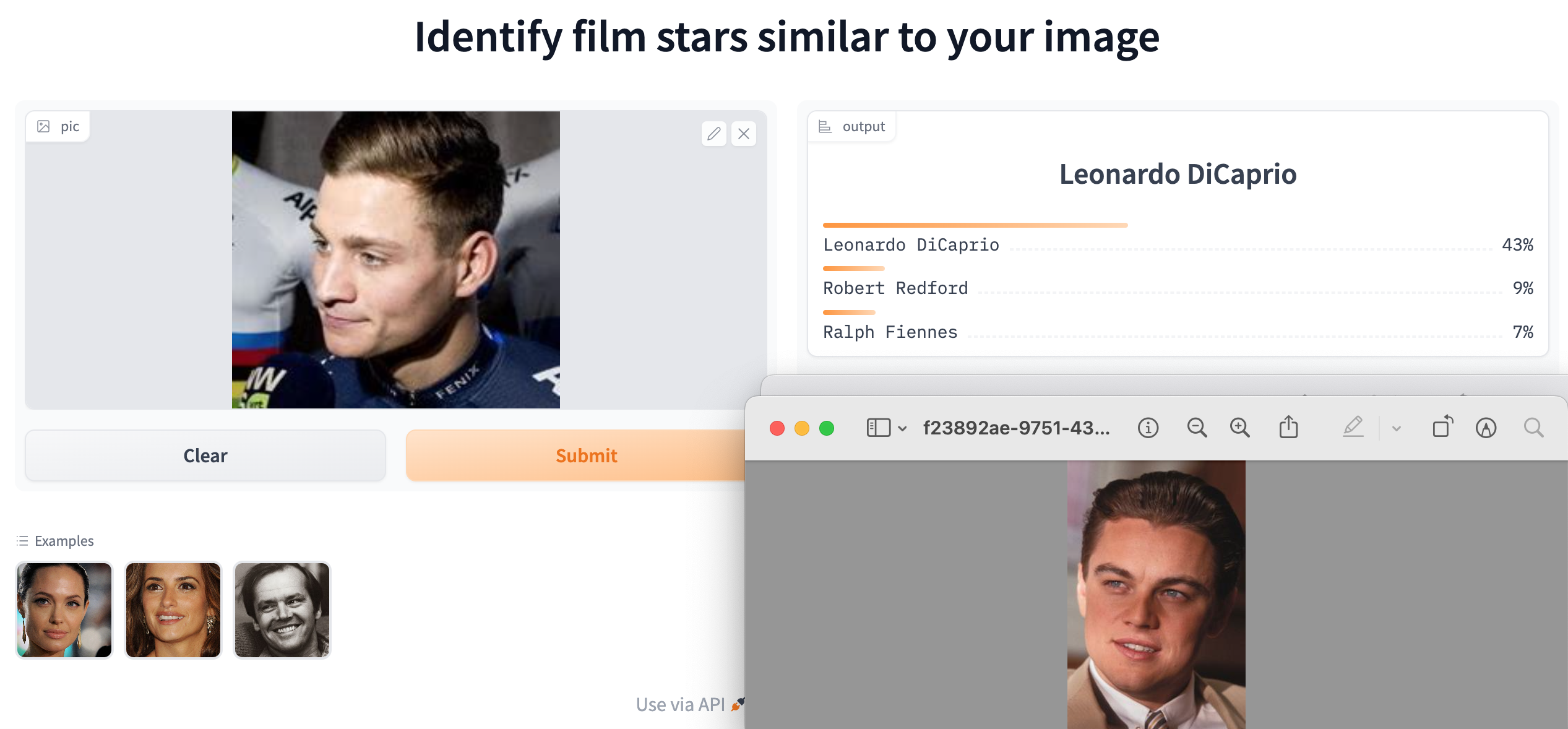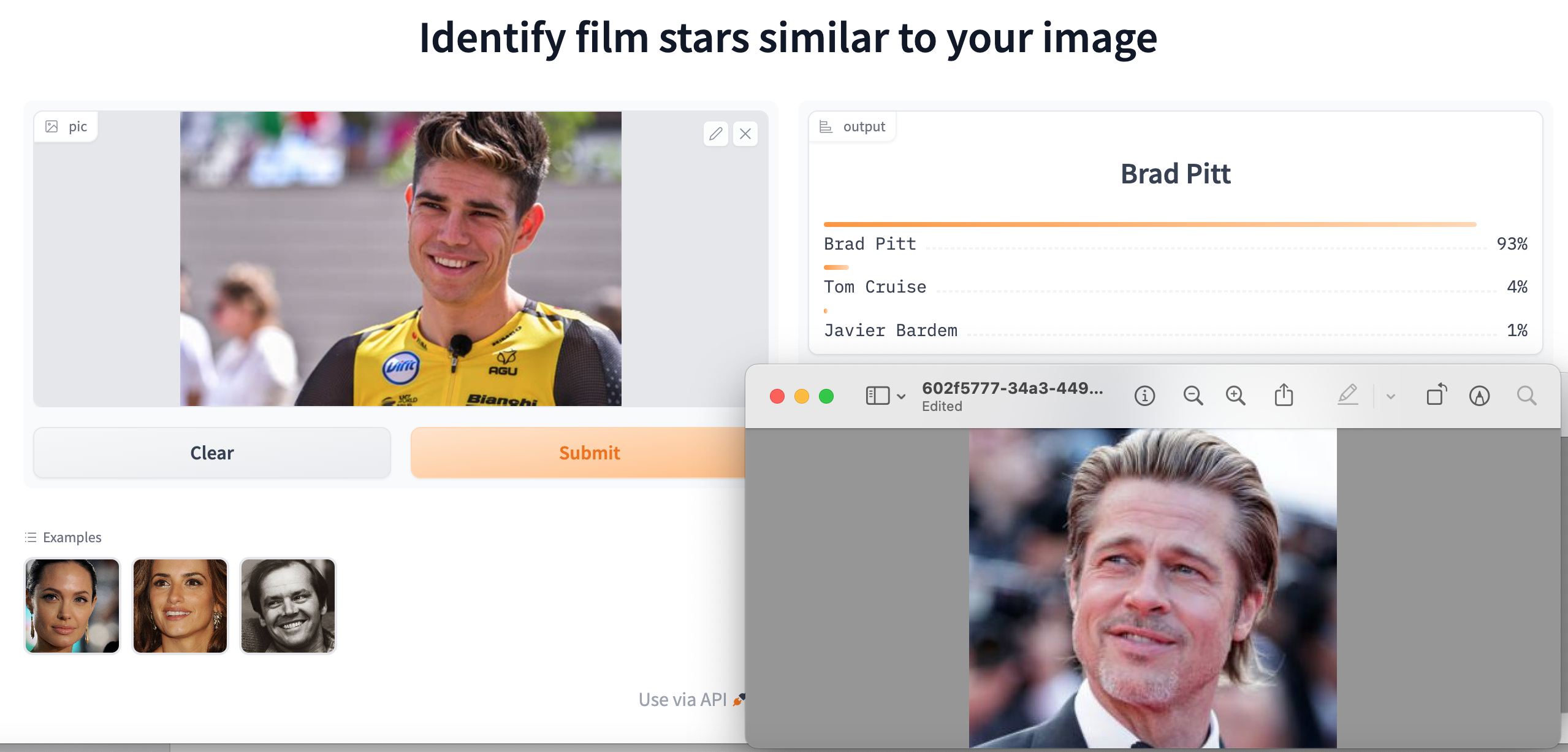
When Mexico’s Isaac del Toro and the Brit, Finlay Pickering, joined World Tour teams in 2024, they became part of an elite group. The structure of the professional cycling community differs from other types of social network, because the sport is organised around close-knit teams. You may have heard of the idea that everyone in the world is connected by six degrees of separation. Many social networks include key individuals who act as hubs linking disparate groups. How closely connected are professional cyclist? Which cyclists are the most connected?
Forming a link
An obvious way for cyclists to become acquainted is by being part of the same team. They spend long periods travelling, training, eating and relaxing together, often sharing rooms. Working as a team through the trials and tribulations of elite competition develops high degrees of camaraderie.
Each rider’s page on ProCyclingStats includes a team history. So I checked the past affiliations of all the current UCI world team riders. The idea was to build a graph where each node represented a rider, with edges connecting riders who had been in the same team. Each edge was weighted by the number of years a pair of riders had been in the same team, reflecting the strength of their relationship.
Cyclo-social network
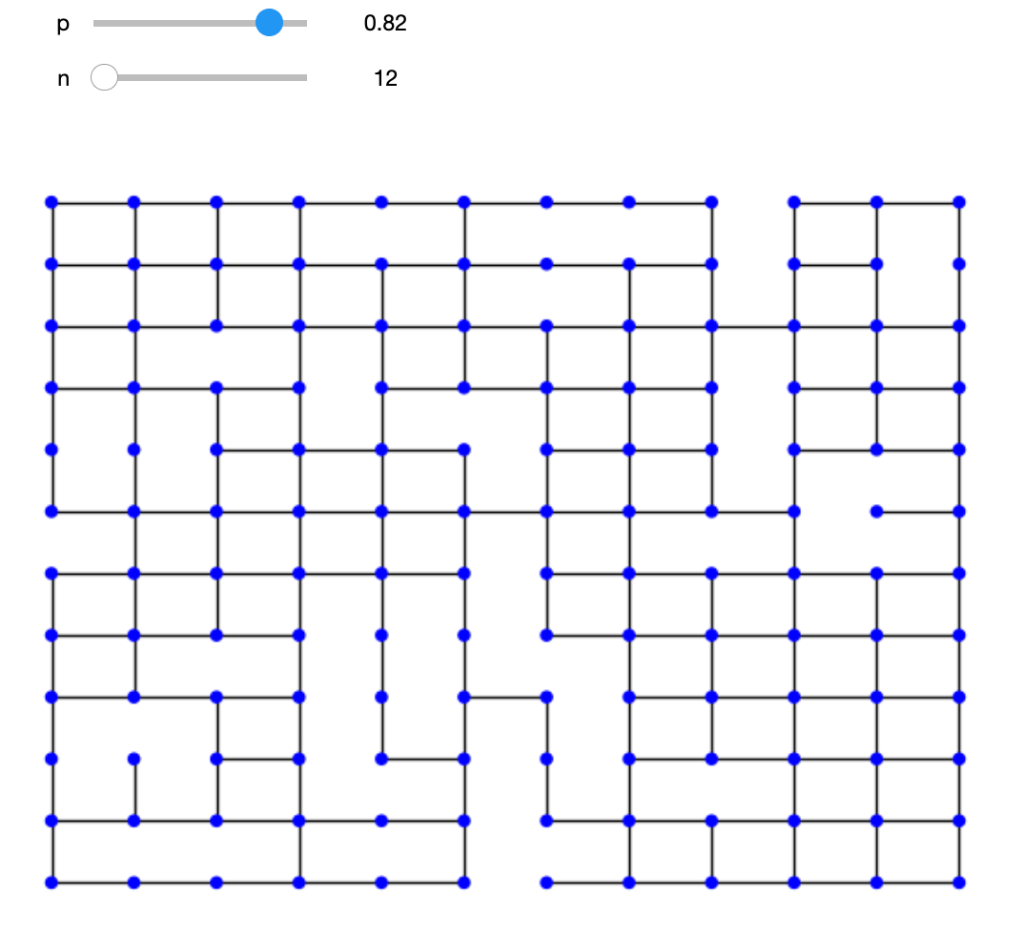
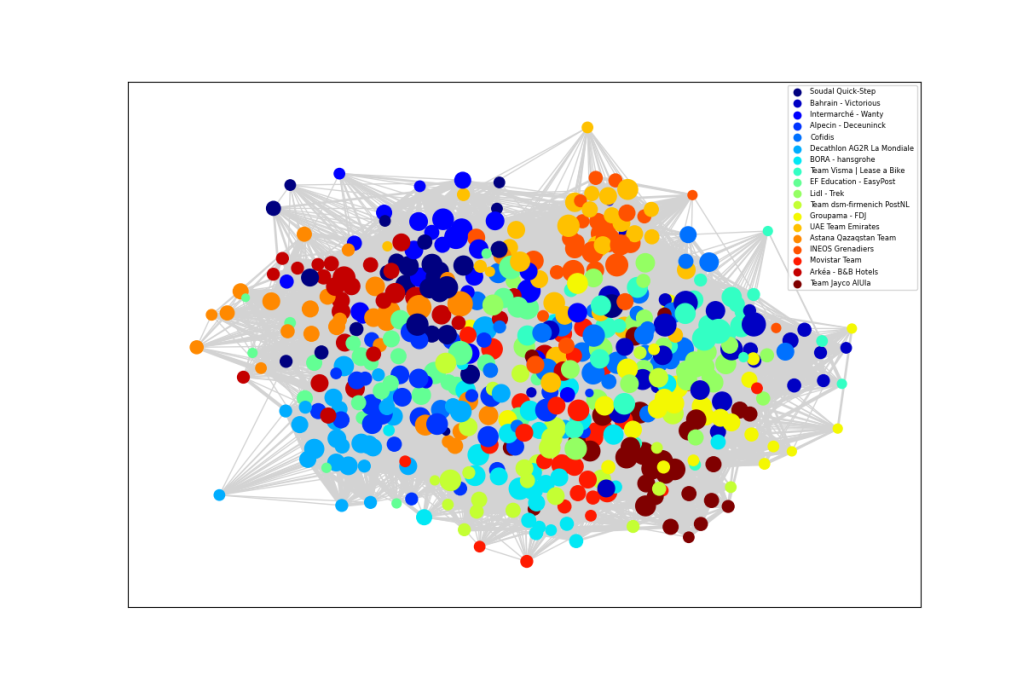
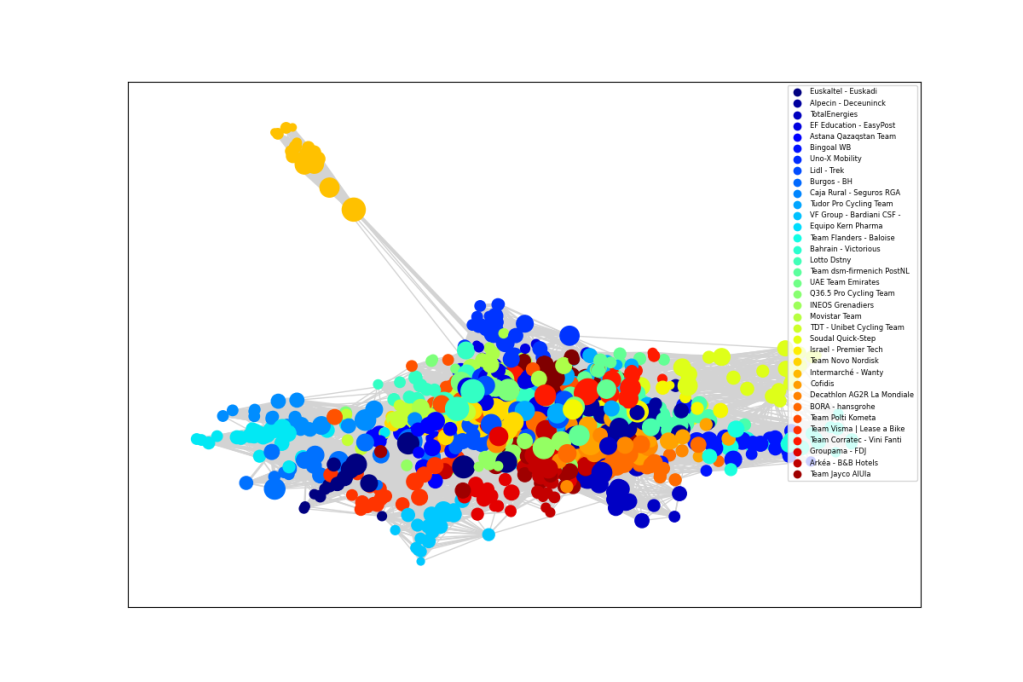
The resulting graphical network, displayed at the top of this blog, has some interesting properties that reveal the dynamics of professional cycling. The 18 world tour teams are displayed in different colours. The size of each rider node is scaled by length of career. An experienced rider, like Geraint Thomas, has a larger node and more connections, which are shown as light grey lines, where the thickness represents years in the pair of riders were in the same team. Newer riders, with fewer connections tend to be on the periphery. For example, Isaac del Toro is the orange UAE Team Emirates rider at the top.
There are no fixed rules about how to represent the network, but the ideas is that more closely related riders ought to congregate together. The network shows INEOS near UAE as shades of orange in the top right. Next we have Team Visma Lease a Bike in cyan, around two o’clock, close to Lidl – Trek in light green, Bahrain – Victorious in darker blue and Cofidis in lighter blue. Yellow Groupama – FDJ lies above the dark brown Jayco AlUla riders in the lower right. Red Movistar, light green Team dsm-firmenich PostNLand light blue BORA – Hansgrohe are near 6 o’clock, though Primož Roglič lies much closer to his old team. Decathlon AG2R La Mondiale is light blue in the lower left, near the darker blue of Alpecin – Deceuninck and pale green EF Education – EasyPost. Astana is orange, around nine o’clock. Dark blue Soudal Quick-Step, lighter blue Intermarché – Wanty and red Arkéa – B&B Hotels all hover around the top left. Teams that are more dispersed would be indicative of higher annual turnover.
3 degrees of separation
No rider is more than three steps from any other. In fact the average distance between riders is two steps, because the chances are that two riders have ridden with someone in common over their careers. Although the neo-pros are obviously more distantly connected, Isaac del Toro rides with Adam Yates, who spent six years alongside Jack Haig at Michelton Scott, but who now rides for Bahrain Victorious as a teammate of Finlay Pickering.
Bob Jungels is the most connected rider, having been a teammate of 100 riders in the current peloton. Since 2012, he has ridden for five different teams. He and Florian Senechal are only two steps from all riders. The Polish rider Łukasz Wiśniowski has been with six teams and has 94 links. Then we have Mark Cavendish with 91 and Rui Costa with 89.
In contrast, taking account of spending multiple years as teammates, Geraint Thomas tops the list with 218 teammate years. Interestingly, he is followed by Jonathan Castroviejo, Salvatore Puccio, Michal Kwiatkowski, Luke Rowe, Ben Swift, all long-time colleagues at INEOS Grenadiers. This suggests they are very happy (or well paid) staying where they are.
If we estimate “long-term team loyalty” by number of teammate years divided by number teammates, Geraint is top, followed by Salvatore Puccio, Michael Hepburn, Luke Durbridge, Luke Rowe, Simon Yates and Jasper Stuyven.
Best buddies
The riders who have been teammates for the longest are Luke Durbridge/ Michael Hepburn and Robert Gesink/Steven Kruijswijk both 15 years,
Geraint Thomas has ridden with Ben Swift and Salvatore Puccio for 14 years and Luke Rowe with Salvatore Puccio for 13.
Outliers
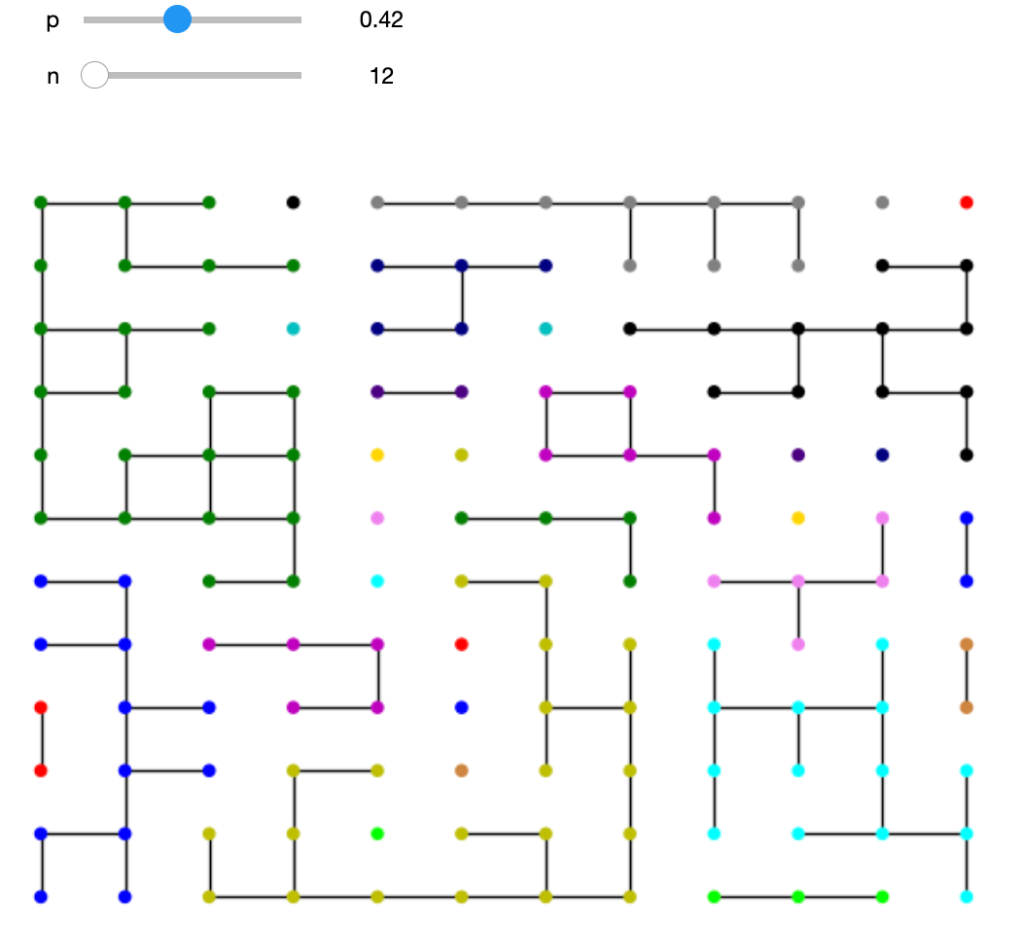
In a broader analysis that includes all the Pro Continental teams alongside the World Tour, the graph below shows a notable team of outliers. This is Team Novo Nordisk for athletes compete with type 1 diabetes. Their Hungarian rider, Peter Kusztor, was the teammate of several current riders, such as Jan Tratnik, prior to joining Novo Nordisk, in a career that stretches back to 2006. The team is an inspiration to everyone affected by diabetes.
Analysis
This analysis was performed in Python, using the NetworkX library.
Code can be found here.